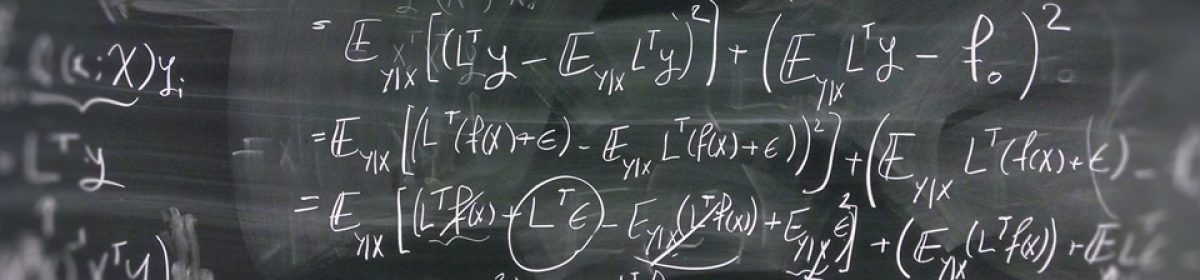
We just uploaded a preprint on spectral analysis of weighted Laplacians that arise as the continuum limits of graph Laplacian operators often used in clustering semi-supervised learning. There are some surprising results pertaining to different normalizations of graph Laplacians. Turns out, they are not equivalent and the continuum limit operators can behave quite differently.
https://arxiv.org/abs/1909.06389
Abstract:
Graph Laplacians computed from weighted adjacency matrices are widely used to identify geometric structure in data, and clusters in particular; their spectral properties play a central role in a number of unsupervised and semi-supervised learning algorithms. When suitably scaled, graph Laplacians approach limiting continuum operators in the large data limit. Studying these limiting operators, therefore, sheds light on learning algorithms. This paper is devoted to the study of a parameterized family of divergence form elliptic operators that arise as the large data limit of graph Laplacians. The link between a three-parameter family of graph Laplacians and a three-parameter family of differential operators is explained. The spectral properties of these differential perators are analyzed in the situation where the data comprises two nearly separated clusters, in a sense which is made precise. In particular, we investigate how the spectral gap depends on the three parameters entering the graph Laplacian and on a parameter measuring the size of the perturbation from the perfectly clustered case. Numerical results are presented which exemplify and extend the analysis; in particular the computations study situations with more than two clusters. The findings provide insight into parameter choices made in learning algorithms which are based on weighted adjacency matrices; they also provide the basis for analysis of the consistency of various unsupervised and semi-supervised learning algorithms, in the large data limit.
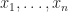


 is allowed to decay to zero at a slow enough rate as the number of data points grows. This rate depends on the intrinsic dimension of the manifold on which the data is supported.
is allowed to decay to zero at a slow enough rate as the number of data points grows. This rate depends on the intrinsic dimension of the manifold on which the data is supported.
